


Revolusi DeepSeek-V3.2: Saat Open Source Akhirnya Menjegal GPT-5? Bedah Tuntas Teknologi “Sparse Attention” & Agentic AI

Desember 2025 menjadi bulan yang mengejutkan bagi dunia kecerdasan buatan. Saat kita semua mengira dominasi closed-source seperti GPT-5 (OpenAI) dan Gemini 3.0 Pro (Google DeepMind) sudah tidak terbendung, tiba-tiba muncul penantang serius dari kubu open-source.
Perkenalkan: DeepSeek-V3.2.
Jujur saja, sebagai pengamat teknologi yang sering menulis di grafisify.com, saya sempat skeptis. Biasanya, model open-source selalu tertinggal 6-12 bulan di belakang model berbayar. Namun, laporan teknis terbaru membuktikan sebaliknya. DeepSeek-V3.2 tidak hanya “mendekati” kinerja model top-tier, tapi varian khususnya (DeepSeek-V3.2-Speciale) bahkan berhasil mengalahkan GPT-5 dalam tugas penalaran matematika dan coding tingkat olimpiade.
Artikel ini akan membedah secara mendalam (deep-dive) bagaimana DeepSeek melakukan “sihir” teknologi bernama DeepSeek Sparse Attention (DSA) dan bagaimana hal ini akan mengubah cara kita bekerja di masa depan. Siapkan kopi Anda, ini akan panjang!
Deep Dive: Inovasi di Balik DeepSeek-V3.2
Apa rahasia di balik lonjakan performa ini? Berdasarkan dokumen teknis arXiv:2512.02556v1 yang dirilis tim DeepSeek-AI, ada tiga pilar utama yang menjadi pondasi model ini:
1. DeepSeek Sparse Attention (DSA): Efisiensi Tanpa Kompromi
Masalah terbesar LLM (Large Language Models) saat ini adalah “Context Window”. Semakin panjang teks yang Anda masukkan (misalnya 100 halaman dokumen hukum), semakin lambat dan mahal komputasinya. Ini karena arsitektur standar menggunakan mekanisme Dense Attention yang kompleksitasnya $O(L^2)$. Artinya, jika panjang teks naik 2x lipat, beban kerja komputer naik 4x lipat.
DeepSeek-V3.2 memperkenalkan DSA (DeepSeek Sparse Attention). Sederhananya begini:
“Bayangkan Anda membaca buku tebal. Model lama membaca setiap kata di setiap halaman untuk mencari jawaban (Dense). DSA bekerja seperti manusia cerdas yang menggunakan ‘Indeks Kilat’ (Lightning Indexer) untuk langsung melompat ke paragraf yang relevan saja (Sparse).”

Secara teknis, DSA mengurangi kompleksitas komputasi menjadi $O(Lk)$, di mana $k$ adalah jumlah token terpilih yang jauh lebih kecil dari total panjang teks ($L$). Hasilnya? Model ini bisa memproses konteks super panjang (Long Context) dengan biaya yang jauh lebih murah dan kecepatan lebih tinggi, tanpa mengorbankan akurasi. Brilliant, right?
2. Scalable Reinforcement Learning (RL) Framework
Anda mungkin ingat fenomena DeepSeek-R1 atau model “Thinking” lainnya. Di V3.2, mereka menyempurnakan resep Reinforcement Learning (RL). Mereka mengalokasikan anggaran komputasi *post-training* yang sangat besar (lebih dari 10% biaya pre-training) untuk melatih model “berpikir”.
Mereka menggunakan algoritma GRPO (Group Relative Policy Optimization) yang lebih stabil. Dengan metode ini, model dilatih untuk melakukan penalaran panjang (Chain-of-Thought) sebelum menjawab. Hasilnya, varian DeepSeek-V3.2-Thinking mampu bersaing *head-to-head* dengan GPT-5 dalam logika kompleks.
3. Pipeline Tugas Agenik Skala Besar (Agentic Task Synthesis)
Ini bagian favorit saya. Kelemahan model open-source biasanya bodoh saat disuruh menggunakan alat (tool-use), misalnya browsing internet atau menjalankan kode Python. DeepSeek mengatasi ini dengan membuat Data Sintetis secara massal.
Mereka membangun sistem yang secara otomatis menghasilkan lebih dari 85.000 lingkungan simulasi agen dan prompt yang rumit. Model dilatih untuk tidak hanya “menjawab”, tapi “bertindak”. Contohnya dalam merencanakan perjalanan liburan yang kompleks dengan budget ketat, model ini bisa melakukan pencarian berulang, verifikasi harga hotel, dan menghitung total biaya secara mandiri sebelum memberikan jawaban final kepada pengguna.
Analisis Dampak: Apa Artinya Bagi Kita?
Kehadiran DeepSeek-V3.2 bukan sekadar berita bagi peneliti AI, tapi punya dampak nyata bagi industri dan pengguna:
- Demokratisasi Kecerdasan Super: Karena ini model terbuka (meski lisensinya perlu dicek detail), developer indie dan startup bisa memiliki kemampuan setara Google/OpenAI tanpa biaya API yang mencekik. Ini bisa memicu ledakan aplikasi AI baru di 2026.
- Penurunan Harga API Global: Efisiensi DSA memungkinkan biaya inferensi (pemakaian) menjadi sangat murah. Kompetitor terpaksa harus menurunkan harga atau berinovasi lebih jauh. Konsumen yang diuntungkan!
Catatan Editor: Lihat Figure 3 pada paper asli untuk grafik perbandingan biaya (Cost Per Million Tokens) yang menunjukkan betapa murahnya inferensi V3.2 dibandingkan versi sebelumnya. - Asisten Coding yang Lebih Jago: Varian Speciale mendapatkan medali emas di IOI 2025 (International Olympiad in Informatics). Bagi programmer, ini berarti *copilot* di IDE Anda akan semakin jarang melakukan halusinasi kode. Wkwk, siap-siap kerjaan makin santai (atau makin terancam?).
Komparasi Head-to-Head: The Battle of Titans
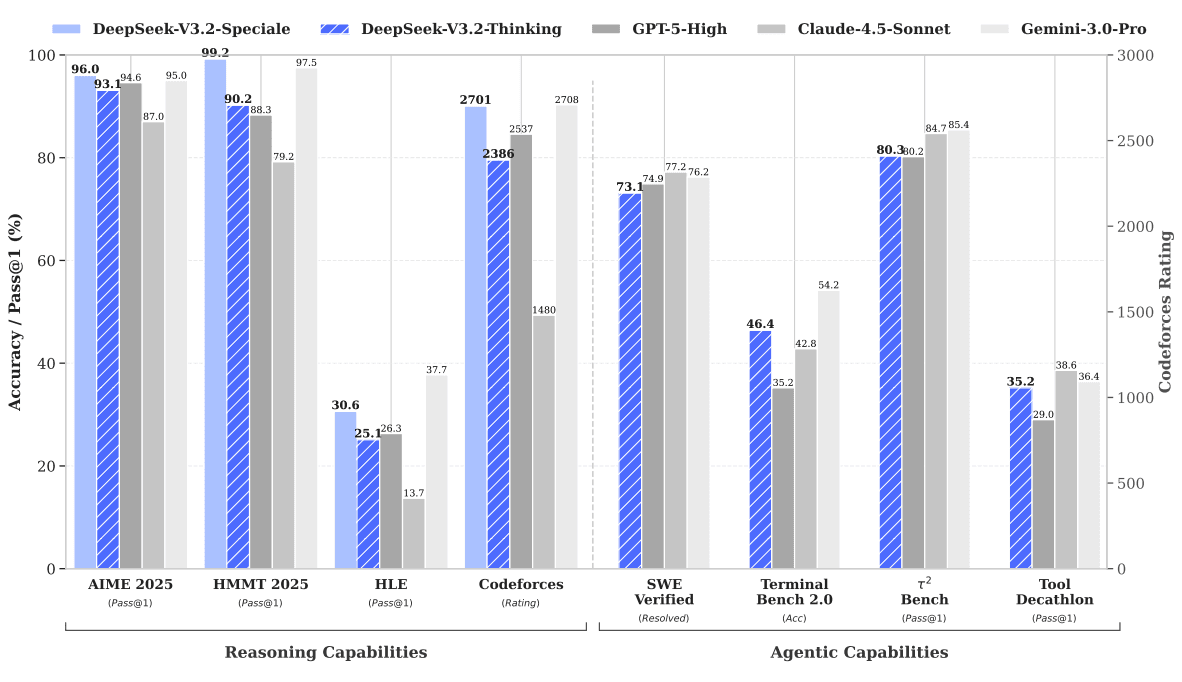
Mari kita lihat data faktualnya. Berdasarkan benchmark teknis, berikut perbandingan DeepSeek-V3.2 melawan para raksasa industri per Desember 2025.
| Benchmark / Kategori | DeepSeek-V3.2 (Speciale) | GPT-5 (High) | Gemini 3.0 Pro | Claude 4.5 Sonnet |
|---|---|---|---|---|
| Matematika (AIME 2025) | 96.0% (Juara!) | 94.6% | 95.0% | 87.0% |
| Coding (Codeforces Rating) | 2701 | 2537 | 2708 | 1480 |
| Software Engineering (SWE-Verified) | 73.1% (Thinking) | 74.9% | 76.2% | 77.2% |
| Status | Open Weights (Available) | Closed (Proprietary) | Closed (Proprietary) | Closed (Proprietary) |
Analisis Tabel:
Bisa dilihat, varian DeepSeek-V3.2-Speciale benar-benar “monster”. Di matematika (AIME 2025), ia mengalahkan GPT-5 High. Di dunia coding kompetitif (Codeforces), ia menempel ketat Gemini 3.0 Pro dengan rating 2701 vs 2708. Perbedaan yang sangat tipis! Padahal, Gemini 3.0 Pro adalah model tertutup milik Google yang sumber dayanya nyaris tak terbatas.
Opini & Prediksi Masa Depan
Menurut pandangan kami, langkah DeepSeek menggunakan arsitektur Sparse Attention adalah game changer. Selama ini, banyak yang mengira kita butuh hardware makin besar untuk AI makin pintar. DeepSeek membuktikan kita butuh algoritma yang lebih pintar, bukan cuma GPU yang lebih banyak.
Prediksi:
- Teknologi Sparse Attention akan diadopsi massal oleh model open-source lain (seperti Llama atau Mistral) dalam 3-6 bulan ke depan.
- Fokus persaingan 2026 bukan lagi soal “siapa yang paling pintar menjawab chat”, tapi “siapa yang paling jago menggunakan tools (Agentic)”.
- Akan muncul hibrida baru: Model kecil di laptop (on-device) yang menggunakan teknik Sparse ini untuk memproses dokumen ribuan halaman tanpa koneksi internet.
FAQ: Pertanyaan Umum Seputar DeepSeek-V3.2
Apakah DeepSeek-V3.2 lebih bagus dari GPT-5?
Tergantung penggunaannya. Untuk penalaran matematika murni dan logika (reasoning), varian Speciale terbukti mengalahkan skor benchmark GPT-5 High. Namun, untuk pengetahuan umum (General Knowledge) dan tugas kreatif, model proprietari seperti GPT-5 mungkin masih unggul sedikit karena data training yang lebih masif.
Apa itu DeepSeek Sparse Attention (DSA)?
DSA adalah teknologi baru yang memungkinkan AI memproses teks panjang dengan cara memilih informasi penting saja (seperti membaca indeks buku), bukan membaca kata per kata secara berurutan. Ini membuat AI jauh lebih cepat dan hemat memori.
Apakah model ini gratis untuk digunakan?
DeepSeek dikenal sebagai pahlawan Open Source. Biasanya mereka merilis bobot model (weights) untuk komunitas. Namun, untuk menjalankannya, Anda tetap butuh GPU yang kuat, atau menggunakan layanan API mereka yang terkenal sangat murah.
Bisakah DeepSeek-V3.2 melakukan coding?
Sangat bisa! V3.2 mencapai performa tingkat medali emas di olimpiade informatika (IOI 2025). Kemampuannya menyelesaikan masalah pemrograman kompleks setara dengan engineer senior.
Apa bedanya versi “Thinking” dan standar?
Versi “Thinking” menggunakan teknik Chain-of-Thought yang diekspos. Ia akan “berpikir” dan merenung dulu (menghasilkan teks internal) sebelum memberikan jawaban akhir. Ini membuatnya jauh lebih akurat untuk soal logika, matematika, dan coding.
Referensi & Sumber Berita: DeepSeek-V3.2 Technical Report (arXiv)
AI BenchmarkAI Coding AssistantDeepSeekDeepSeek-SpecialeDeepSeek-V3.2Gemini 3.0 Progenerative aiGPT-5IOI 2025Large Language ModelOpen Source AIReinforcement LearningSparse AttentionTech News 2025