




Kandinsky 5.0 Rilis! Pesaing Berat Sora, Veo 3 & Flux dengan Arsitektur CrossDiT: Bedah Tuntas Model Video AI Open-Source Terganas Saat Ini

Halo sobat teknologi! Kembali lagi bersama saya di sini. Jujur saja, tahun ini rasanya kita dihajar habis-habisan sama perkembangan AI yang nggak ada rem-nya. Belum kering ingatan kita soal kehebohan Sora dari OpenAI atau Veo dari Google, sekarang muncul lagi penantang baru yang nggak main-main: Kandinsky 5.0.
Kalau kalian sering mampir ke blog saya di grafisify.com, kalian pasti tahu betapa saya bawel soal pentingnya Open Source. Nah, Kandinsky 5.0 ini datang membawa angin segar—atau mungkin badai—buat industri generatif AI. Bukan cuma sekadar rilis model, tim Kandinsky Lab merilis sebuah “Keluarga Besar” model fondasi yang mencakup Text-to-Image dan Text-to-Video dengan kualitas yang diklaim setara, bahkan di beberapa aspek mengalahkan model tertutup (closed-source) raksasa.

Di artikel Deep-Dive kali ini, kita nggak cuma bakal bahas kulit luarnya aja. Kita akan bedah jeroannya, mulai dari arsitektur CrossDiT, teknik Flow Matching, hingga rahasia dapur mereka dalam memproses data. Siapkan kopi kalian, karena ini bakal panjang dan *daging* banget! Let’s dive in!
Pendahuluan: Sebuah Lompatan Evolusi dari Kandinsky
Sejarah Kandinsky sebenarnya cukup panjang. Dimulai dari model autoregresif sederhana di 2021, mereka berevolusi menjadi Diffusion Model di versi 2.0, hingga akhirnya di Kandinsky 5.0 ini mereka melakukan perombakan total. Ini adalah model pertama mereka yang menggunakan paradigma Flow Matching—sebuah teknik generasi yang dianggap lebih stabil dan efisien dibandingkan metode difusi tradisional.

Yang bikin saya geleng-geleng kepala (haha), mereka nggak nanggung-nanggung merilis tiga lini model sekaligus:
- Kandinsky 5.0 Image Lite (6B Parameter): Spesialis gambar resolusi tinggi dan editing.
- Kandinsky 5.0 Video Lite (2B Parameter): Versi “ringan” tapi ngebut buat video 10 detik.
- Kandinsky 5.0 Video Pro (19B Parameter): Si monster utama untuk kualitas video sinematik.
Bayangkan, model 19 Miliar parameter (19B) ini dilatih untuk menghasilkan video hingga resolusi 1024px atau durasi 10 detik dengan koherensi yang gila. Tapi, apa sih rahasia di balik performanya?
Deep Dive: Mengupas Teknologi di Balik Layar
Oke, mari kita masuk ke bagian teknis. Jangan pusing dulu sama istilah-istilahnya, saya akan coba jelaskan dengan bahasa manusia.
1. Arsitektur CrossDiT (Diffusion Transformer)
Kandinsky 5.0 meninggalkan arsitektur U-Net lama dan beralih ke Diffusion Transformer (DiT). Tapi, mereka memodifikasinya menjadi apa yang disebut CrossDiT.
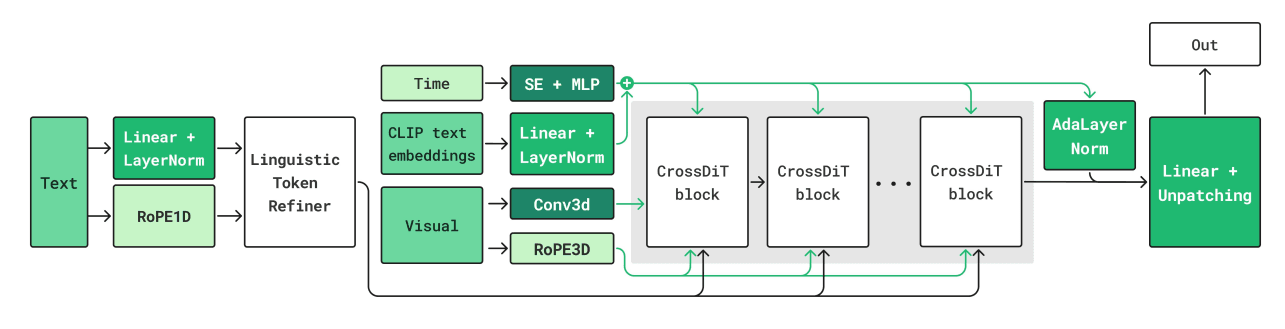
Jadi begini, model ini menerima input teks (prompt kita) dan visual (gambar/video) secara bersamaan. Untuk teks, mereka menggunakan encoder Qwen2.5-VL (salah satu model bahasa visual terbaik saat ini). Nah, alih-alih menggabungkan (concatenate) semua data ini yang bikin berat proses training, mereka menggunakan mekanisme Cross-Attention.
“Keunggulan arsitektur Cross-Attention ini adalah kompatibilitasnya yang lebih baik dengan mekanisme sparse attention, yang sangat krusial untuk memproses video dengan panjang durasi yang bervariasi.” — Tim Kandinsky Lab.
Artinya, model ini lebih pintar memilah mana informasi teks yang relevan untuk setiap frame video tanpa harus memproses sampah data yang nggak perlu.
Baca juga:
2. Inovasi NABLA: Kunci Kecepatan
Ini adalah bagian favorit saya. Masalah utama model video AI adalah “biaya” komputasi. Semakin panjang videonya, semakin “kuadratik” beban memorinya. Di sinilah Kandinsky memperkenalkan NABLA (Neighborhood Adaptive Block-Level Attention).

Apa itu NABLA?
Bayangkan kalian harus mengawasi 100 murid di lapangan. Cara lama (Full Attention) adalah kalian menatap setiap murid satu per satu setiap detik. Capek kan? NABLA ini seperti kalian membagi murid jadi kelompok-kelompok kecil, lalu kalian cuma fokus menatap kelompok yang sedang aktif bergerak saja.
Secara teknis, NABLA mengurangi kompleksitas perhatian (attention map) dengan cara:
- Dimensionality Reduction: Meringkas query dan key dalam blok-blok kecil.
- Adaptive Sparsification: Membuang koneksi yang tidak relevan (membuatnya “sparse” atau jarang).
Hasilnya? Training dan inferensi (proses generate) jadi 2.7x lebih cepat tanpa mengurangi kualitas video. Gokil sih ini.
3. Pipeline Data yang “Brutal”
Model AI itu ibarat koki; kalau bahan makanannya busuk, masakannya pasti nggak enak. Kandinsky 5.0 dilatih menggunakan dataset yang diproses secara gila-gilaan:
- T2I Dataset: 500 Juta pasang teks-gambar.
- T2V Dataset: 250 Juta klip video.
Tapi bukan cuma jumlahnya. Mereka melakukan filterisasi ketat: mendeteksi watermark (biar videonya nggak ada logo stock footage), menilai estetika menggunakan model AI lain (seperti Q-Align), hingga membuang video yang terlalu statis atau terlalu goyang. Mereka bahkan punya dataset khusus bernama RCC (Russian Cultural Code) untuk memastikan model paham konteks budaya lokal mereka, yang menurut saya strategi cerdas agar AI nggak bias ke budaya barat saja.
Baca juga:
Analisis Dampak: Apa Artinya Buat Kita?
Rilisnya Kandinsky 5.0 ini punya dampak besar, terutama karena sifatnya yang condong ke Open Source (bobot model dan kodenya tersedia untuk komunitas riset).
1. Demokratisasi Video High-End
Selama ini, kualitas video setara Sora cuma bisa diakses lewat API berbayar atau antrean tunggu yang panjang. Dengan adanya Kandinsky Video Lite (2B), developer independen atau startup kecil bisa menjalankan model video AI di server yang lebih terjangkau. Ini membuka peluang aplikasi mobile baru untuk bikin konten sosmed instan.
2. Standar Baru Kualitas vs Efisiensi
Adanya metode Distillation (penyulingan model) yang mereka terapkan, membuat model ini bisa berjalan dengan langkah (steps) yang lebih sedikit. Varian “Flash” dari model ini bisa generate video hanya dengan 16 langkah (NFE), dibandingkan model biasa yang butuh 50-100 langkah. Buat industri periklanan yang butuh turnaround cepat, ini game changer.
Komparasi: Kandinsky 5.0 vs The World (Termasuk Veo 3)
Biar adil, mari kita adu spesifikasi dan klaim performanya. Data ini berdasarkan laporan teknis dan evaluasi manusia (Human Eval) yang mereka lakukan, termasuk melawan raksasa baru dari Google, Veo 3.

Prompt Following remained a relative weakness compared to Veo 3 variants
| Fitur / Metrik | Kandinsky 5.0 Video Pro | Veo 3 (Google) | Sora (OpenAI) |
|---|---|---|---|
| Parameter | 19 Miliar (19B) | Tertutup | Tertutup (>20B) |
| Arsitektur | CrossDiT + Flow Matching | Latent Diffusion Transformer | DiT + Patches |
| Video Quality | Sangat Tinggi (Unggul di Dinamika Gerak) | Tinggi | Sangat Tinggi |
| Prompt Following | Cukup Baik | Sangat Baik (Juara) | Sangat Baik |
| Aksesibilitas | Open Weights & Code | Closed / API Only | Closed / API |
Analisis Head-to-Head dengan Veo 3:
Berdasarkan data Human Evaluation (SBS), ada temuan menarik saat Kandinsky 5.0 Video Pro diadu dengan Veo 3.
- Kemenangan Veo 3: Veo 3 menang telak dalam hal Prompt Following. Artinya, kalau kalian kasih instruksi teks yang super rumit dan detail, Veo 3 lebih “nurut” dan akurat menerjemahkan teks ke video.
- Kemenangan Kandinsky: Mengejutkannya, Kandinsky 5.0 Video Pro justru unggul dalam skor Video Quality dan Motion Dynamics. Gerakan objek di Kandinsky dinilai lebih natural, halus, dan estetika visualnya lebih memukau mata (sinematik) dibanding Veo 3, meskipun kadang ada detail instruksi teks yang terlewat.
Jadi, pilihannya kembali ke kebutuhan: butuh akurasi instruksi (Veo 3) atau keindahan visual & gerakan natural (Kandinsky)?
Opini & Prediksi Masa Depan
Sebagai seseorang yang sering mengulik tools AI untuk grafisify.com, saya melihat Kandinsky 5.0 ini sebagai “kuda hitam”. Kenapa?
- Fokus pada Editing: Model Image Lite mereka dilatih khusus dengan dataset instruksi editing. Artinya, kita bisa ngomong “Ganti bajunya jadi warna merah” tanpa merusak wajah karakter. Ini fitur yang sangat dibutuhkan desainer grafis.
- Sinergi Teks & Gambar: Penggunaan Qwen2.5-VL sebagai encoder teks adalah langkah cerdas. Model ini “melek visual”, jadi dia lebih paham deskripsi posisi (spasial) dibanding encoder teks biasa.
Prediksi saya: Dalam 6 bulan ke depan, kita akan melihat banyak tools web berbasis Kandinsky 5.0 yang menawarkan jasa bikin video iklan murah meriah. Dan teknik NABLA bakal dicontek—eh maksudnya diadopsi—oleh model-model open source lain karena efisiensinya.
Kekurangannya? Hardware. Menjalankan model 19B parameter tetap butuh VRAM monster (H100 atau cluster A100). Jadi, buat kalian yang pakai GPU gaming rumahan, mungkin harus puas main-main sama versi Lite (2B) atau versi Image-nya saja. Yah, syukuri apa yang ada, wkwk.
FAQ: Pertanyaan yang Sering Muncul
Q: Apakah Kandinsky 5.0 gratis digunakan?
A: Model ini dirilis dengan lisensi MIT (untuk kode) dan bobot modelnya terbuka untuk riset. Jadi ya, gratis untuk diunduh dan dijalankan sendiri, selama Anda punya hardware yang mumpuni.
Q: Spesifikasi PC apa yang dibutuhkan untuk menjalankan Kandinsky 5.0?
A: Untuk versi Image Lite (6B) dan Video Lite (2B), kemungkinan besar bisa jalan di GPU consumer high-end (seperti RTX 3090/4090 dengan VRAM 24GB). Namun, untuk Video Pro (19B), Anda butuh hardware kelas server atau multi-GPU setup.
Q: Apa bedanya Flow Matching dengan Diffusion biasa?
A: Sederhananya, Diffusion biasa itu seperti menghilangkan noise (semut di TV) secara acak sampai jadi gambar. Flow Matching itu lebih seperti menarik garis lurus dari titik noise ke titik gambar jadi. Jalurnya lebih efisien, jadi prosesnya lebih cepat dan stabil.
Q: Di mana saya bisa mencoba Kandinsky 5.0?
A: Biasanya model ini akan segera tersedia di Hugging Face (akun kandinskylab) atau platform demo AI. Pantengin terus update di grafisify.com buat tutorial cara install-nya nanti ya!
Baca juga:
Referensi & Sumber Berita: Kandinsky Lab GitHub / arXiv Technical Report
AI NewsFlow MatchingFlux Alternativegenerative aigrafisifyKandinsky 5.0Kandinsky LabNABLA AttentionOpen Source AISora CompetitorTeknologi AI TerbaruText-to-ImageVeo 3 ComparisonVideo AI